智能算法部署关键过程-ONNX转换
ONNX(Open Neural Network Exchange)
介绍
1. ONNX 的基本概念和背景
ONNX(Open Neural Network Exchange)是一个开放源代码的深度学习模型交换格式和生态系统。它由 Facebook 和 Microsoft 于 2017 年共同发布,旨在作为不同深度学习框架之间的通用模型表示标准 (Open Neural Network Exchange - Wikipedia)。
ONNX 提供了一种开放标准,用于表示机器学习模型和神经网络算法,方便模型在不同的框架和工具之间迁移 (Open Neural Network Exchange - Wikipedia)。简单来说,ONNX 就像是一种通用语言或中间表示(IR),可以描述深度学习模型的计算图和权重,使得各个框架训练得到的模型可以互相转换和共享 (Open Neural Network Exchange (ONNX) Explained | Splunk)。
ONNX 项目最初代号为 “Toffee”,由 Facebook 的 PyTorch 团队开发,后来在 2017 年 9 月正式更名为 ONNX,并得到多家公司的支持(如 IBM、华为、英特尔、AMD、Arm、Qualcomm 等) (Open Neural Network Exchange - Wikipedia)。2019 年 ONNX 正式加入 Linux 基金会,成为其 AI 项目的毕业级项目之一。这些背景体现了 ONNX 社区的开放性和行业广泛支持。
2. ONNX 的主要特性
ONNX 作为机器学习模型的开放标准格式,具备以下主要特性:
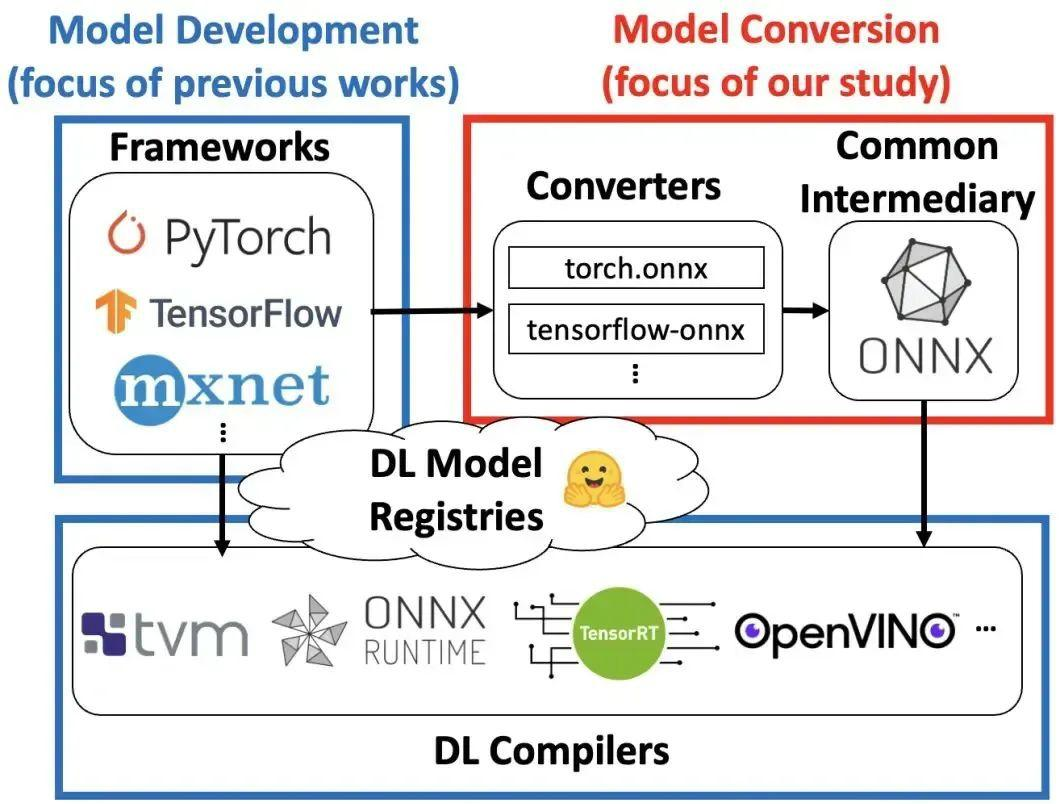
框架互操作性:ONNX 最核心的特性就是框架无关性和互操作性。模型可以在一个框架(如 PyTorch、TensorFlow)中训练,然后导出为 ONNX 格式,在另一个框架或推理引擎中加载和运行。这允许开发者在不同工具间自由切换,而不被某单一生态锁定 (Open Neural Network Exchange (ONNX) Explained | Splunk) (Announcing ONNX Support for Apache MXNet | AWS Machine Learning Blog)。例如,你可以用 PyTorch 方便地构建和训练模型,再用 ONNX 将模型部署到移动设备的推理引擎中执行。
可移植性与平台无关:ONNX 模型是通过 protobuf 序列化的 .onnx 文件,可以在各种硬件和操作系统上运行。借助 ONNX,模型可以方便地部署到云侧(云服务、服务器)、端侧(边缘设备甚至移动应用)中 (Open Neural Network Exchange (ONNX) Explained | Splunk)。这种通用格式减少了因部署环境差异而重写模型的需求。
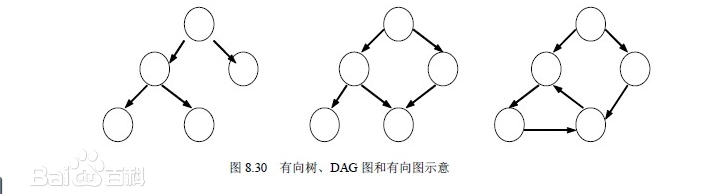
计算图表示:ONNX 定义了一种可扩展的计算图模型来表示神经网络。一个 ONNX 模型由有向无环图(DAG)的节点组成,每个节点表示一个操作符(Operator),节点之间的有向边表示张量数据的流动 (Open Neural Network Exchange - Wikipedia)。计算图中包含模型的网络结构(层与层的连接关系)、每个节点的输入输出张量名和类型,以及模型的参数权重(以张量常量形式存储)。这种图结构使模型的结构清晰且易于优化。
标准算子和数据类型:ONNX 内置了一套标准的算子(Operators)和数据类型库。各个支持 ONNX 的框架都会实现这些标准算子,以确保一致的计算结果 (Open Neural Network Exchange - Wikipedia)。常见的深度学习算子(如卷积、池化、全连接、激活函数等)都在 ONNX 的算子库中定义,并有版本(opset)管理以支持新特性扩展。这保证了模型在不同框架上执行的一致性 (Open Neural Network Exchange (ONNX) Explained | Splunk)。ONNX 也定义了常用的张量数据类型(如 float32、int64、BOOL 等),使模型交换时数据格式统一。
扩展性:ONNX 设计时考虑了扩展性,新版本可以引入新的算子集(OpSet)而不破坏向后兼容。对于非常新的或自定义的算子,ONNX 支持定义自定义算子域以扩展功能。此外,ONNX 不仅支持深度神经网络,也支持传统机器学习模型(称为 ONNX-ML),包括决策树、随机森林、支持向量机等,使其成为通用的机器学习模型交换格式。
专注推理(Inference):ONNX 格式主要侧重于模型的推理阶段表示。它涵盖了模型前向传播所需的一切(计算图、运算、权重),但不直接包含训练过程中反向传播的信息(目前也有用于训练的扩展,但不常用)。这种专注使 ONNX 模型更简洁高效,非常适合部署和推理。换言之,ONNX 提供的计算图定义和算子主要聚焦于推理/评估用途 (Open Neural Network Exchange - Wikipedia)。
性能优化友好:由于采用统一的计算图和算子标准,各种底层优化技术(如算子融合、内存复用等)可以直接针对 ONNX 模型进行。这为后续的推理引擎优化打下基础。许多硬件厂商也支持直接对 ONNX 模型进行加速优化,这意味着针对 ONNX 的一次优化能同时提升多个框架的性能 (Open Neural Network Exchange - Wikipedia)。在 ONNX 生态中,我们也可以方便地对模型进行图优化和量化(后续介绍),以进一步提高推理速度和减小模型大小。
3. ONNX 如何在深度学习模型之间进行转换
ONNX 的出现大大简化了不同深度学习框架之间模型转换的工作。过去如果想将模型从一个框架转换到另一个,往往需要耗费数周甚至数月编写转换脚本或重新实现模型 (theano - Is there a common format for neural networks - Stack Overflow)。而借助 ONNX 标准,模型转换可以更简单和快速地完成 (theano - Is there a common format for neural networks - Stack Overflow)。
典型的转换流程是:在源框架中将模型导出为 ONNX 格式,然后在目标环境中加载该 ONNX 模型进行推理。许多主流框架都提供了导出或转换工具,例如:
在 PyTorch 中,可以使用内置的 torch.onnx.export 接口将 PyTorch 模型导出为 ONNX 文件。
对于 TensorFlow/Keras,有第三方工具如 tf2onnx 或 keras2onnx,用于将 TensorFlow 的计算图或 Keras 保存模型转换为 ONNX。
MXNet 提供了 mx2onnx 和 onnx2mx 工具,可实现 MXNet 和 ONNX 之间的双向模型转换。
还有像 Microsoft CNTK(Cognitive Toolkit)、Caffe2 等框架,本身对 ONNX 就有内建支持,可以直接导出或导入 ONNX 模型。
转换时,转换器会把源模型的计算图结构和权重映射为等效的 ONNX 计算图和张量。如果源模型中使用的算子属于 ONNX 标准算子集,那么转换通常是无损的。一旦模型被转换为 ONNX 格式,就相当于拥有了一个框架中立的模型表示;这个 ONNX 模型可以在任何支持 ONNX 的引擎或库中载入运行,或者再转换到其他框架中去 (Deploying models converted to ONNX format)。例如,可以在 PyTorch 中训练好模型->导出ONNX->然后在 TensorFlow (通过 ONNX 导入工具) 或直接在 ONNX Runtime 中推理。
需要注意,转换的完整性取决于框架对算子的支持程度。如果模型使用了源框架中特有而 ONNX 尚未支持的算子,转换器可能会失败或需要额外处理(比如自定义算子)。但随着 ONNX 不断扩充算子集,以及社区提供的各种转换工具(包括针对 sklearn、XGBoost、LightGBM 等的转换器),大部分常见模型都能顺利在框架间迁移。
总的来说,ONNX 提供了一个统一桥梁,极大降低了深度学习模型跨框架转换的门槛,实现了一次训练、多处部署的灵活性 (Open Neural Network Exchange (ONNX) Explained | Splunk)。
4. ONNX 的生态系统(如 ONNX Runtime)
围绕 ONNX 标准,已经形成了一个丰富的生态系统,包括推理引擎、模型库和开发工具等:
ONNX Runtime:这是由微软主导开发的高性能跨平台推理引擎。ONNX Runtime 可以加载 ONNX 模型并在多种硬件上高效运行 (Deploying models converted to ONNX format)。它针对推理进行了大量优化(比如图优化、算子融合等),并提供了多种执行后端 (Execution Providers),以利用不同硬件的加速能力。例如,ONNX Runtime 支持CPU执行(默认)、GPU执行(CUDA/cuDNN)、OpenVINO(英特尔加速)、TensorRT(英伟达TensorRT加速)、NNAPI(移动端加速)等。通过选择合适的执行提供器,ONNX Runtime 能充分利用硬件特性,实现高效的模型推理 (Deploying models converted to ONNX format)。ONNX Runtime 提供了多语言的API(包括 Python、C++、C#、Java、JavaScript 等),方便在不同开发环境中使用。同一个 ONNX 模型文件,可以在服务器(x86 CPU/GPU)、移动设备(ARM CPU/GPU)、浏览器(WebAssembly/WebGPU)等各种平台上通过 ONNX Runtime 来运行,做到“一次训练,随处部署”。
ONNX Model Zoo:ONNX 模型动物园是社区提供的预训练模型集合 (onnx/models: A collection of pre-trained, state-of-the-art ... - GitHub)。里面包含许多常用的深度学习模型(例如 ResNet50、BERT、YOLO 等)已经转换好的 ONNX 文件,开发者可以直接下载使用。模型动物园的存在方便了快速试用和部署 ONNX 模型,并展示了 ONNX 在不同任务上的应用范例。
转换和优化工具:在 ONNX 生态下,有许多工具帮助创建、转换和优化模型。例如:
onnx库:官方的 ONNX Python 库,可用于程序matically 构建或操作 ONNX 模型,检查模型格式有效性等。
转换器:如前述的 tf2onnx, keras2onnx, skl2onnx(Scikit-Learn 转 ONNX), onnxmltools 等,将不同框架的模型导出为 ONNX。
ONNX Optimizer:有一些库可以对 ONNX 模型进行简化或优化,比如 onnx-simplifier(简化计算图)、polish 工具等,或者直接使用 ONNX Runtime 提供的优化 API。
量化工具:ONNX Runtime 提供了量化工具,可以将浮点模型转换为低比特模型(如 int8),以提高推理速度和减小模型大小。
社区与支持:ONNX 在 2017 年推出后,迅速得到各大厂商和开源社区的支持,形成了一个开放合作的生态 (Announcing ONNX Support for Apache MXNet | AWS Machine Learning Blog)。Linux 基金会托管了 ONNX 项目,确保其中立性和开放性。
众多硬件厂商(Intel、NVIDIA、ARM、Qualcomm、AWS 等)都参与 ONNX,在各自平台上支持 ONNX 模型的加速。比如 NVIDIA 的 TensorRT 可以直接加载 ONNX 模型做高性能推理;Intel 的OpenVINO支持将 ONNX 模型部署在CPU/FPGA/VPU上;安卓平台的NNAPI也逐步支持ONNX模型格式等。这些共同努力让 ONNX 成为了事实上的跨框架、跨平台模型格式标准。
ONNX 不只是一个文件格式,而是围绕模型标准化所构建的一个完整生态。开发者可以利用 ONNX,从模型开发、格式转换到最终部署,一路都有配套的工具和运行时支持,大大简化机器学习项目的流程。
5. ONNX 的优化和量化技术
ONNX 优化和量化是ONNX生态中用于提升模型推理性能、减小模型体积的重要技术手段:
优化技术
计算图优化(Graph Optimizations):ONNX 模型在推理前可以通过一系列图优化来简化和加速计算。ONNX Runtime 就提供了多级别的图优化机制 (Graph optimizations | onnxruntime)
基本优化:移除冗余节点、常量折叠等。这类优化在不改变模型功能的前提下,删除计算图中多余的计算。例如,常量折叠会静态计算图中与常量相关的子计算,将结果直接写入模型,从而减少运行时的计算 (Graph optimizations | onnxruntime)。又如去除恒等运算、合并连续的reshape等。
扩展优化:更复杂的算子融合和内存布局调整等。这些通常发生在针对特定硬件的子图上,例如将一组操作融合为一个高效内核。比如卷积层和后面的批归一化、ReLU可以融合成一个算子执行,以减少内存读写和计算开销 (Graph optimizations | onnxruntime)。再如,将多个小矩阵乘法加和融合成大的GEMM等。
图优化可以在模型加载时在线进行(加载模型后即时优化),也可以离线进行(事先将优化后的模型保存以加快每次启动)。经过优化的 ONNX 模型通常计算图更紧凑、执行效率更高 (Graph optimizations | onnxruntime)。这些优化由 ONNX Runtime 自动完成,开发者也可以使用 onnxoptimizer 等工具手动优化模型。
算子级别优化:除了结构性的图优化,不同硬件的执行提供器也会对某些ONNX算子进行特定优化实现。例如,GPU上用高度并行的CUDA核函数实现Conv算子,CPU上利用向量化指令优化MatMul等。这些优化属于底层实现,但因为ONNX算子标准化,硬件厂商只需针对ONNX算子优化即可适配所有使用该算子的模型(这也是 ONNX “一次优化,多处适用”的理念体现 (Open Neural Network Exchange - Wikipedia))。
量化技术
模型量化(Quantization):量化是将模型从高精度(如FP32)转换为低精度(如INT8、UINT8)的过程,以换取更快的推理速度和更小的模型尺寸。ONNX Runtime 提供了成熟的量化工具和API,可对 ONNX 模型进行动态或静态量化 (Quantize ONNX models | onnxruntime):
动态量化(精度高):在动态量化中,模型的权重通常量化为 INT8,而激活值(中间计算结果)在推理时动态计算量化参数(scale和zero-point)并量化 (Quantize ONNX models | onnxruntime)。也就是说,不需要预先用校准数据确定激活的量化范围,而是在每次推理时根据当前批次数据动态调整。这会带来一些运行时开销(需要实时计算量化参数),但通常能取得比静态量化更高的精度,因为保留了对每批输入动态调整的灵活性 (Quantize ONNX models | onnxruntime)。动态量化使用方便,不需要校准过程。典型应用是对 NLP 模型(如 Transformer、BERT)进行动态量化,它们的全连接权重很多,量化后大幅减少矩阵乘法开销,同时保持良好的精度。
静态量化(效率高):静态量化需要在量化前进行校准(calibration)。开发者需要提供一组代表性输入数据跑过模型,收集各层激活值的分布范围 (Quantize ONNX models | onnxruntime)。然后选择合适的算法(如MinMax、KL散度等)确定每个张量的量化缩放因子和零点,并将这些量化参数嵌入到模型中 (Quantize ONNX models | onnxruntime)。之后模型的推理就使用固定的量化参数,将权重和激活统一用INT8(或者部分用INT8)计算。静态量化通常能带来最大的性能提升(因为整个推理过程中都是低精度计算,无需动态计算量化系数),但相对可能引入更多精度损失,尤其如果校准数据不足以代表实际数据分布。静态量化常用于卷积神经网络(CNN)等在图像领域的模型,在CPU上能显著加速推理。
量化感知训练 (QAT):除上述事后量化外,有些框架支持在训练过程中加入量化仿真(即量化感知训练),直接训练出对低精度鲁棒的模型,再转换为量化后的 ONNX 模型。这种方法往往精度损失最小,但实现和训练成本较高。ONNX 模型可以表示通过 QAT 得到的量化算子(ONNX 有 QuantizeLinear/DequantizeLinear 等节点以及 QDQ 格式支持)。
ONNX Runtime 的量化工具支持上述动态和静态量化流程,并提供API如 quantize_dynamic() 和 quantize_static() 一键量化模型 (Quantize ONNX models | onnxruntime) (Quantize ONNX models | onnxruntime)。经过量化的模型会在计算图中插入量化/反量化节点或者直接将算子替换为量化算子,使模型以 8 位整数进行计算。量化模型通常大小缩减(约为原1/4,如果从FP32到INT8)、CPU上推理延迟降低(利用向量化的INT8指令),非常适合对延迟敏感或资源受限的部署场景。
混合精度:除了整型量化,ONNX 也支持使用 FP16(半精度浮点)或 BF16 等混合精度来权衡性能和精度。在部分算子上降为 FP16,可以减小显存占用并提高吞吐,ONNX Runtime 也有相应的模型转 FP16 工具。混合精度通常用于 GPU 上加速,TensorRT 等执行提供器对 FP16 支持很好。
总之,ONNX 不仅提供模型交换格式,本身也在模型高效推理方面提供了诸多支持。通过图优化,我们可以精简模型计算图、消除冗余;通过量化和混合精度,我们可以压缩模型和加速推理,同时尽量保证精度可接受。这些优化技术通常可以叠加使用,例如先进行图优化,再执行量化,以获得更好的综合效果。ONNX 及其运行时工具链让开发者能够方便地应用这些优化手段,将模型部署推理的性能发挥到更优。